Недавно в Cloudflare произошёл инцидент, который кратковременно приостановил работу ряда ключевых сервисов, включая Cloudflare R2, Cloudflare Stream, Cloudflare Images и Cache Reserve. Причиной сбоя послужила нештатная попытка заблокировать фишинговую ссылку, из-за чего на протяжении почти одного часа эти сервисы оказались полностью недоступны для пользователей по всему миру. Несмотря на временные трудности, компания быстро справилась с ситуацией и уже в течение часа восстановила стабильную работу всех затронутых платформ.
Причины инцидента и скорость реагирования
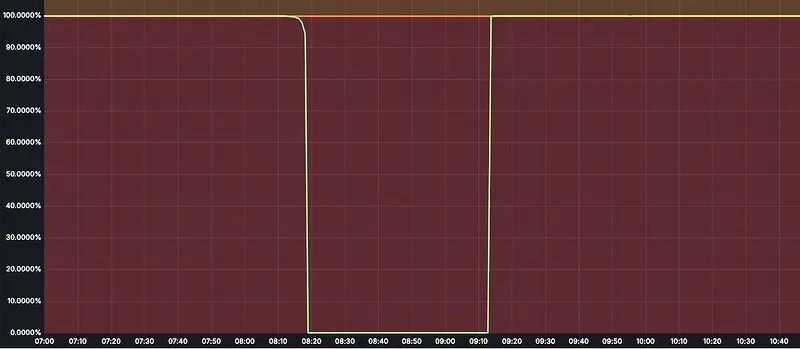
Согласно официальным данным, инцидент произошёл 6 февраля 2025 года и длился 59 минут. Специалисты Cloudflare оперативно опубликовали отчёт, разъясняющий причины и меры устранения. Во время рутинной процедуры по блокировке фишингового сайта в хранилище Cloudflare R2 была допущена незначительная ошибка в системе управления доступом. В результате этого событие повлияло на R2 Gateway — ключевой компонент, обеспечивающий взаимодействие с API облачного хранилища. Эта цепочка событий привела к временному прекращению работы сервисов Stream, Images, Cache Reserve, Vectorize, Log Delivery и Key Transparency Auditor.
Cloudflare хорошо известен на рынке благодаря передовым возможностям по обеспечению безопасности, высокой доступности и скорости работы для интернет-приложений и сайтов. Компания акцентирует внимание на быстрое реагирование на потенциальные угрозы, с акцентом на защиту корпоративных сетей, масштабируемость и соблюдение принципов Zero Trust. Важно отметить, что несмотря на сбой, ни один байт данных, хранящихся в облачной инфраструктуре Cloudflare, не был утерян или повреждён — все пользовательские данные остались в полной сохранности.
Влияние на основные сервисы и аналитика последствий
В течение почти часа полностью приостановили свою работу такие сервисы, как Cloudflare Stream (загрузка и доставка видеоконтента), Cloudflare Images (работа с изображениями), Cache Reserve (обеспечение резервного кэша), а также Vectorize и Log Delivery. У Key Transparency Auditor наблюдались 100% сбои в публикации и чтении подписей. Для Vectorize статистика показала, что 75% запросов завершались ошибками, а операции вставки и удаления оказались полностью недоступны.
В косвенной степени задержки и неполадки коснулись Durable Objects, где фиксировалось увеличение ошибок на 0,09% из-за повторных подключений, а также Cache Purge, где наблюдался рост ошибок HTTP 5xx на 1,8% и увеличение задержек в десять раз. На Workers & Pages проблемы затронули около 0,002% развертываний (только те проекты, которые были напрямую связаны с R2).
Примечательно, что после возникновения сбоя команда Cloudflare немедленно инициировала внутренний аудит и процесс восстановления работы всех сервисов. Уже спустя 59 минут функционирование R2, Stream, Images, Cache Reserve, Vectorize, Log Delivery и Key Transparency Auditor было полностью восстановлено.
Быстрый возврат к стабильности
Cloudflare наглядно продемонстрировала профессионализм своей команды и зрелость процессов реагирования на инциденты. Наличие автоматизированных систем мониторинга и гибкость команд DevOps позволили устранить ситуацию в кратчайшие сроки. Благодаря детальному внутреннему расследованию, была выявлена и устранена причина инцидента — человеческий фактор и недостаточная защита от ошибок при администрировании, связанные с обработкой жалоб на фишинговые ссылки.
Руководство компании подчёркивает свой ориентир на постоянное совершенствование внутренних инструментов контроля и администрирования. Внедрение дополнительных уровней валидации и автоматизации уже запущено и будет неуклонно обеспечивать ещё большую надежность ключевых сервисов: Cloudflare R2, Cloudflare Stream, Cache Reserve и других.
Позитивные перемены и уроки для будущего
Этот случай стал для Cloudflare ещё одной возможностью усилить механизмы предотвращения сбоев и усовершенствовать процессы внутреннего аудита. Команда компании отмечает, что каждый подобный инцидент позволяет не только быстрее реагировать в будущем, но и создавать более прочные решения для защиты глобальной сети клиентов. Акцент на проактивной безопасности и автоматизации гарантирует, что сервисы Cloudflare будут становиться всё более устойчивыми и надёжными для миллионов пользователей по всему миру.
Изначальной причиной временного отключения стали действия по защите пользователей от фишинговых атак, что подчёркивает главную задачу Cloudflare — обеспечение безопасности и доверия своих клиентов. Опыт, полученный во время этого сбоя, уже позволил компании обновить внутренние регламенты и добавить новые уровни автоматической проверки на этапе администрирования и технической поддержки.
Cloudflare — курс на инновации и максимальную надёжность
Несмотря на сложившуюся ситуацию, Cloudflare в очередной раз доказала свой высокий уровень компетентности и быструю реакцию команды. Развитие облачных технологий, таких как R2, Stream, Images, Cache Reserve, Vectorize, Log Delivery и связанных сервисов, остаётся в числе ключевых приоритетов. Компания уже поделилась планами по дополнительной защите инфраструктуры и совершенствованию платформы, что гарантирует стабильную и безопасную работу сервисов для всех клиентов — от индивидуальных пользователей до крупных корпораций.
Cloudflare продолжает инвестировать в инновации, чтобы их облачные решения были одними из самых надёжных и эффективных в индустрии. Пользователи могут быть уверены: сервисы будут только расти в стабильности, безопасности и скорости, ведь миссия компании — создавать интернет лучше и безопаснее для всех.
Недостаточная защита ИТ-инфраструктуры: причины инцидента
В основе недавнего сбоя в Cloudflare лежала особенность идентификации внутренних учетных записей, которые активно используются командами для разработки, тестирования и эксплуатации сервисов. Обычно для повышения устойчивости и снижения вероятности ошибок создается несколько учетных записей: для разработки, промежуточной среды и для продакшена. Подобный подход позволяет локализовать возможные ошибки, однако не был учтен при настройке систем безопасности, отвечающих за обработку злоупотреблений. Эти системы не смогли различить и заблокировать действия, нацеленные на внутренние учетные записи.
В результате несогласованности настройки платформа позволила оператору по ошибке полностью отключить важный сервис R2 Gateway, вместо ограниченного воздействия на конкретную конечную точку, связанную с обработкой жалоб на злоупотребления. Это случилось из-за отсутствия детализированной сегментации и контроля доступа на уровне системной архитектуры.
Стоит отметить, что архитектура R2 построена так, чтобы Gateway функционировал независимо. Как только специалисты Cloudflare обнаружили причину сбоя, они столкнулись с новым вызовом: для быстрого восстановления работы требовалась команда операторов с ограниченными правами доступа. Специалисты более низкого уровня, хотя и не имеют допуск к критически важной информации, не всегда могут оперативно реагировать на инциденты. Для восстановления работы потребовалось полное повторное развертывание R2 Gateway, чтобы нормализовать маршрутизацию в инфраструктуре.
Восстановление доступа пользователей к R2 и возврат сервисных ошибок к стандартным значениям затронуло и другие связанные сервисы: Stream, Images, Cache Reserve и Vectorize — все они быстро вернулись к стабильной работе после внедренных обновлений.
Реформирование безопасности и новые защитные меры
Разработчики Cloudflare провели тщательный анализ и выявили, что серьезной предпосылкой к происшествию стал человеческий фактор в сочетании с недостатком защитных фильтров и подтверждения существенных изменений. Уже после инцидента компания оперативно внедрила важные обновления и внесла коррективы в процессы.
Первым шагом стало удаление опции отключения сервисов из пользовательских интерфейсов, которыми располагают специалисты по расследованию злоупотреблений. Так удалось свести к минимуму риск случайных отключений при работе с внутренними системами. Кроме того, были дополнительно усилены административные API — новые ограничения не дадут отключить сервисы, работающие на внутренних учетных записях.
Компания Cloudflare развернула инициативу по пересмотру порядка создания внутренних учетных записей для всех сред: разработки, тестирования и эксплуатации. Теперь аккаунты обязательно привязываются к нужной организации, что предотвращает появление «самостоятельных» учетных записей и защищает платформу от повторения подобных инцидентов.
Также ведется работа по сужению круга сотрудников, которым предоставляются полномочия на выполнение операций по отключению сервисов. Подобные действия остаются доступными только для ограниченного числа старших операторов. Появился обязательный процесс двухуровневого подтверждения для особо важных операций – теперь любое крупное изменение допускается только после одобрения двумя ответственными лицами. При необходимости проведения непредусмотренных процедур сотрудник обязан подать обоснованный запрос руководителю или определенному кругу лиц с правом принятия решений.
Дальнейшее усиление контроля выражается в расширении функционала уже существующих систем обнаружения злоупотреблений. Теперь они предотвращают не только случайную блокировку системных хостов, но и любые попытки отключения сервисов, которые завязаны на внутренние аккаунты в инфраструктуре Cloudflare.
Преобразование процессов безопасности: взгляд в будущее
Cloudflare продолжает уделять особое внимание безопасности своей инфраструктуры. После выявленного сбоя создан сценарий для быстрого разворачивания актуальных обновлений: это и внедрение дополнительных уровней проверки при изменении настроек, и четкая кадровая политика по доступу к критическим сервисам. Разработчики анализируют возникшие ситуации и выстраивают новые алгоритмы не только для защиты от ошибок, но и для быстрой адаптации к возможным угрозам.
В перспективе планируется ещё больше автоматизировать процессы управления внутренними учетными записями, внедрить адаптивную логику доступа и продолжать совершенствовать ролевую модель. Использование гибких средств контроля корпоративной среды поможет максимально быстро реагировать на любые отклонения и обеспечит надежную защиту компании и ее клиентов.
В компании также запущены образовательные программы для сотрудников, чтобы повысить внимательность и осведомленность штатных специалистов по вопросам цифровой безопасности. Такой системный подход минимизирует вероятность повторения похожих инцидентов и создает задел для технологического роста.
Ответственное управление доступом и кризисные протоколы
Тщательно выстроенная архитектура доступа по сути становится залогом стабильности и доверия к сервису. Четкое разделение ролей, прозрачность действий сотрудников и своевременное реагирование на возможные отклонения формируют надежный фундамент работы. Новые механизмы двухстороннего согласования операций и расширенные административные проверки обеспечивают неизменно высокий уровень контроля.
При необходимости отключения сервисов предусмотрены специальные внутренние процедуры. Любое потенциально опасное действие требует не только объяснения и документирования, но и согласования с ответственными сотрудниками. Такой подход не только снижает влияние человеческого фактора, но и ускоряет процесс восстановления работоспособности при возникновении непредвиденных ситуаций.
Позитивные перемены: доверие и стабильность как приоритет
Преодоление подобных вызовов делает платформу Cloudflare только сильнее. Внимание к деталям, быстрая реакция на инциденты и последовательное развитие внутренних стандартов обеспечивают безопасность на самом высоком уровне. Благодаря постоянному анализу и оперативному внедрению лучших практик компания формирует лояльность среди клиентов и закрепляет репутацию надежного технологического партнера. Каждый шаг направления безопасности направлен на укрепление доверия пользователей и бесперебойную работу всего цифрового пространства Cloudflare.
Компания Cloudflare активно совершенствует свои внутренние процессы, переводя учетные записи на обновленную модель «Организации» еще до официального начала работы этой функции. Среди таких аккаунтов оказалась и производственная учетная запись R2. Однако изначально существовавший механизм устранения нарушений не был снабжен необходимыми средствами защиты, чтобы предотвратить возможные действия в отношении учетных записей внутри организации.
Укрепление защиты и повышение ответственности
Коллектив Cloudflare тщательно анализирует ситуацию и предпринимает дополнительные меры по минимизации любых рисков, связанных как с человеческим фактором, так и с возможными техническими сбоями. Команда понимает важность каждого шага и стремится создать условия, при которых даже потенциальные инциденты будут максимально быстро и эффективно нейтрализованы. Сотрудники компании, осознавая серьезность произошедшего, открыто признают свои ошибки и выражают глубокое сожаление по поводу возникших сложностей.
Работы по реализации новых решений ведутся в сжатые сроки. Новая модель «Организации» предусматривает дополнительные уровни контроля и защиты, что существенно снижает вероятность несанкционированных действий с учетными записями. Такой подход позволяет не только повысить безопасность сервисов Cloudflare, но и демонстрирует ответственность перед клиентами и пользователями. С каждым новым этапом команда совершенствует инфраструктуру компании, что способствует укреплению доверия и устойчиваости процессов внутри компании.
Взгляд в будущее: Рост и инновации
Cloudflare рассматривает сложившуюся ситуацию как ценный опыт и стимул к дальнейшему развитию. На данный момент ведется постоянный мониторинг и внедрение новых мер, направленных на предотвращение подобных инцидентов в будущем. Компания стремится не только исправить текущие недочеты, но и внедрять инновационные решения, которые позволят поддерживать высокий уровень безопасности и надежности всех услуг. Благодаря сплоченной работе команды и ответственному подходу внутренняя культура Cloudflare становится лишь сильнее, а клиенты могут быть уверены в надежности выбранных сервисов.
Источник: www.cnews.ru/





